[I wrote this blog while learning Statistics at Center For Continued Education, Indian Institute of Science, Bangalore during Q1 2016. That was the first Data Science course which I attended. Although the notes are very naive in nature, I prefer to keep this blog mostly as a memory.]
Data which has time as one of the components is called Time Series. Most of the economical data, meteorological data is an example of time series. Time series is related to two types of processes:
- Continuous : Data/Process which always exists. For example, temperature. Temperature is measured at discrete intervals, i.e., discrete samples are being generated from a continuous data.
- Discrete : Process which occurs only at discrete points of time. Probability of occurring of that incident between two discrete points is zero. For example the closing value of sensex. Another example could be number of customers visiting a bank everyday.
Autocorrelation for Time Series
Comparing observation at time t, Y(t) with observation at time t-1, Y(t-1) gives an idea about the relationship between consecutive observations. In this case, the observation Y(t-1) is described as “lagged” by one period. Similarly, it is possible to compare observations lagged by two periods, three periods and so on. The relationship between two observations can be measured by calculating the autocorrelation between the series lagged by 1, 2, 3,… periods.
| Actual Time Series | Time Series lagged by 1 period | Time Series lagged by 2 period |
| 2 | ||
| 4 | 2 | |
| 6 | 4 | 2 |
| 8 | 6 | 4 |
| 10 | 8 | 6 |
Correlation can be computed between column 1 and column 2 as if they were two separate series. However, since they are one and the same series (with a lag of 1 period), it is called autocorrelation. The autocorrelation can be plotted against the lags (lagging by one, two, three,…. periods) to form autocorrelation function (ACF) and the plot is called correlogram. This is a standard process in exploring a time series. It provides a useful information for seasonality, trend-cyclicity etc. An example could be found here.
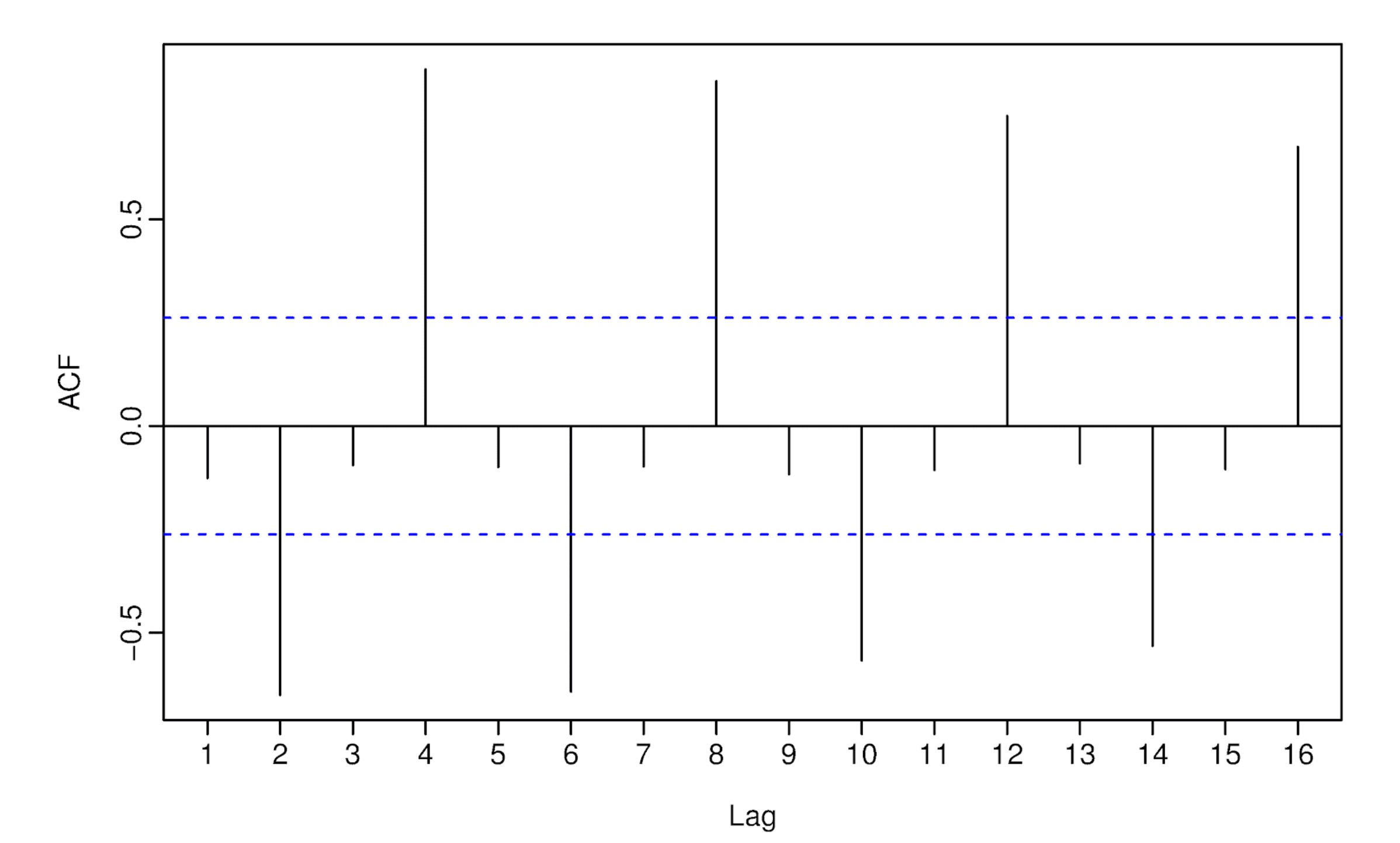
Here, autocorrelation at lag 4 is higher than other lags. This indicates seasonality.
Time Series Components
Decomposition methods (discussed in the next section) assume that Time Series data consists of following components:
- Trend: On a long term if the data series increases or decreases. For example, the population of India is increasing over time.
- Seasonality: Periodic fluctuations of constant length caused by the time of the year, temperature, rainfall, corporate policies etc. For example, demand for the warm clothes in India.
- Cyclicity: This component is measured over a long time duration (one year or longer). For example, buying or selling of property is controlled by the economic recession cycle. Many decomposition techniques considers trend and cyclic as a single component, known as trend-cycle or simply, trend.
- Reminder: Whatever can not be explained using Trend, Seasonality or Cyclicity. For example, impact of sudden rainfall, earthquake or political disturbance.
Decomposition methods tries to analyze each of the components individually.
As per Forecasting: Principles and Practice by Rob J Hyndman, George Athanasopoulos, “Many people confuse cyclic behaviour with seasonal behaviour, but they are really quite different. If the fluctuations are not of fixed period then they are cyclic; if the period is unchanging and associated with some aspect of the calendar, then the pattern is seasonal. In general, the average length of cycles is longer than the length of a seasonal pattern, and the magnitude of cycles tends to be more variable than the magnitude of seasonal patterns.”
Time Series Decomposition
Additive decomposition model assumes the following mathematical model:
Y(t) = T(t) + S(t) + R(t)
Y(t): Actual value of the data at time t
T(t): Trend component at time t
S(t): Seasonal component at time t
R(t): Reminder component at period t
“t” above indicates a specific point of time. This time can be measured in weeks, months, quarters, years or so. For example, sale of warm clothes depends heavily on the time of the year. Due to population growth, it also has a positive trend over time.
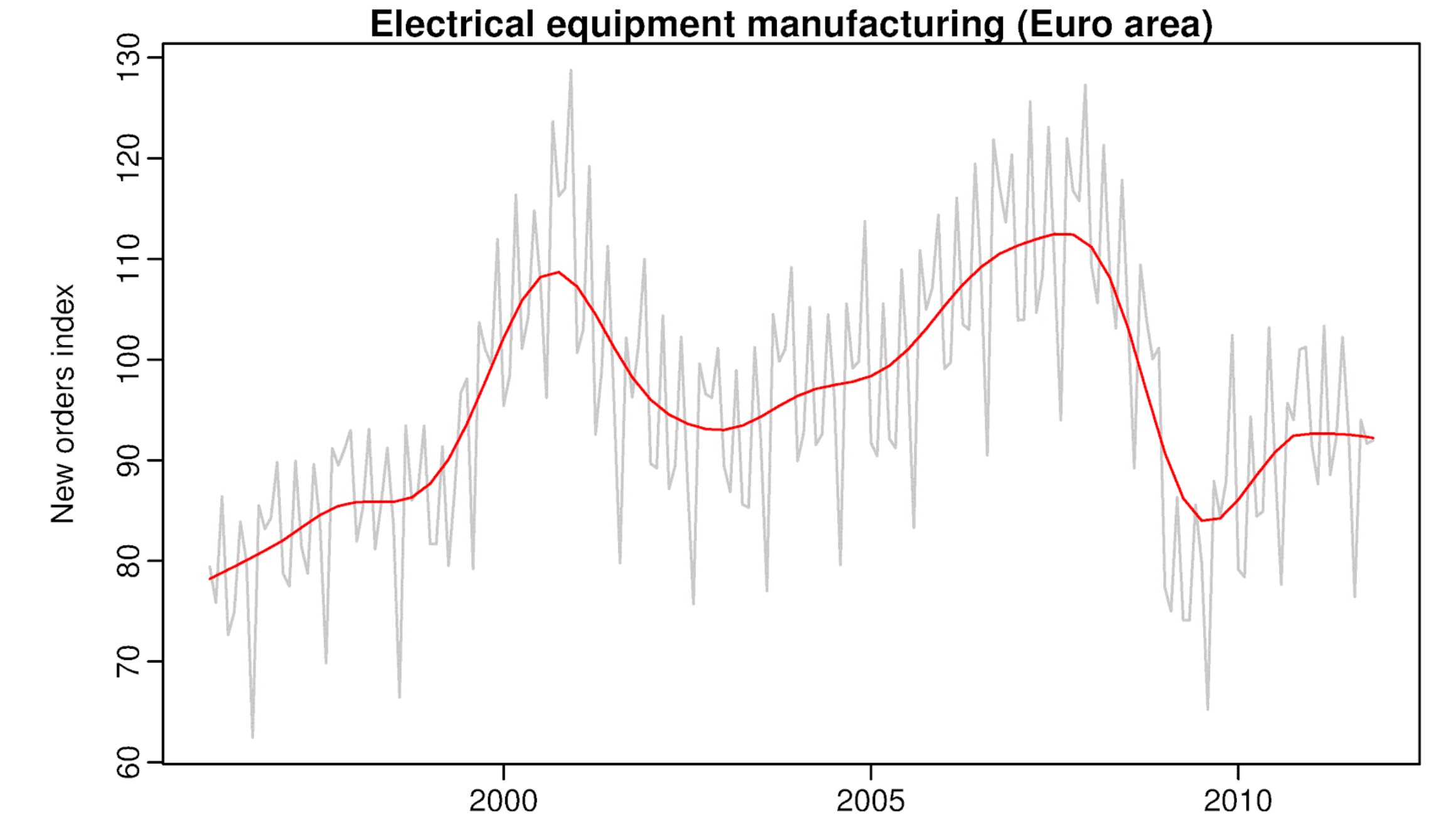
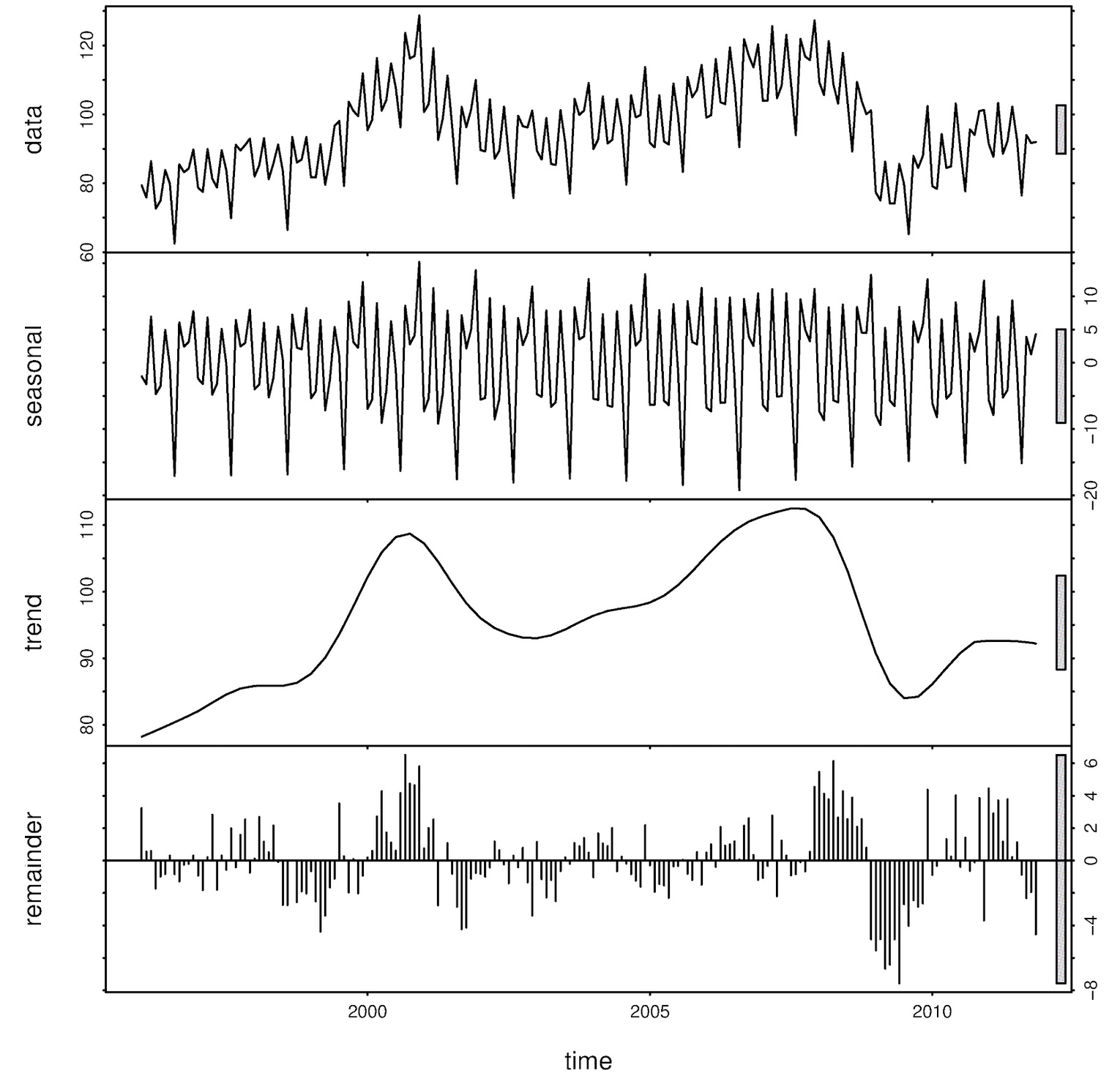
The figure above (from Forecasting: Principles and Practice – Rob J Hyndman, George Athanasopoulos) is about the new order of electric equipment received over time. Raw data in gray, trend-cycle component (ignoring seasonality and randomness/noise) in red. The diagram below shows the additive decomposition of the data.
Smoothing Techniques
Smoothing techniques removes the fluctuations in time series (due to seasonal or reminder components). Once these components are removed only trend-cycle component remains. Moving average and differencing are two smoothing techniques.
- Moving Average
Moving average technique removes the seasonality of the data.
| Index | Actual Data | 3 Moving Average |
| 1 | 103 | |
| 2 | 105 | 293.3 |
| 3 | 672 | 293.6 |
| 4 | 104 | 297 |
| 5 | 115 | 303.3 |
| 6 | 691 | 305 |
| 7 | 110 | 306 |
| 8 | 117 | 291 |
| 9 | 648 |
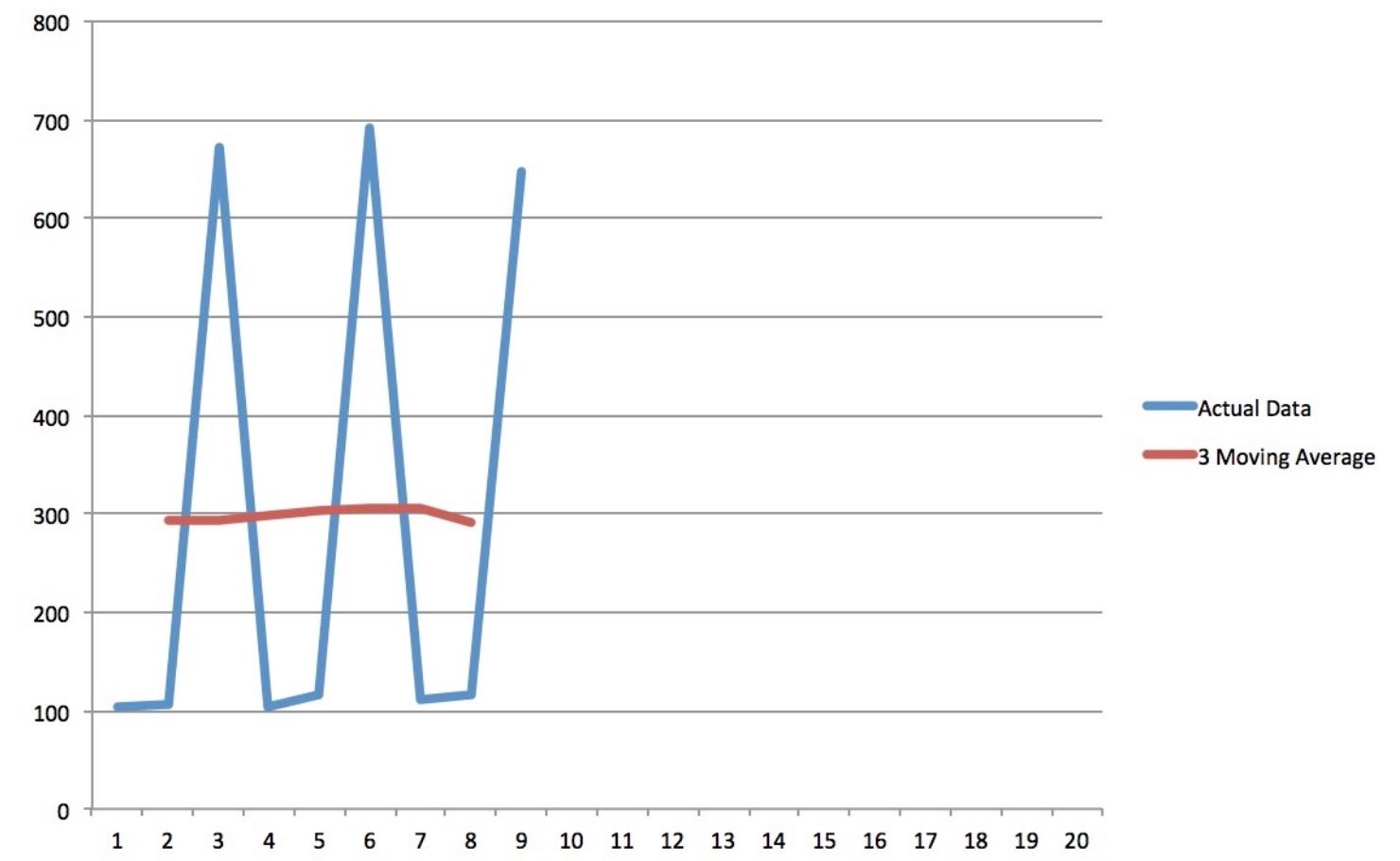
Third column shows the moving average of order 3. The first element (293.3) of the moving average column is the average of the elements 1,2,3 of the actual data column. The second element (293.6) is the average of elements 2,3,4 and so on. Since, we are moving with a block of 3 data points, it’s called 3rd order moving average.
As evident from the figure below, moving average removes the seasonality of the data. If there is no trend in the data set, the transformed data set (after applying moving average) will be around the mean. In that case, mean value will be the best forecast.
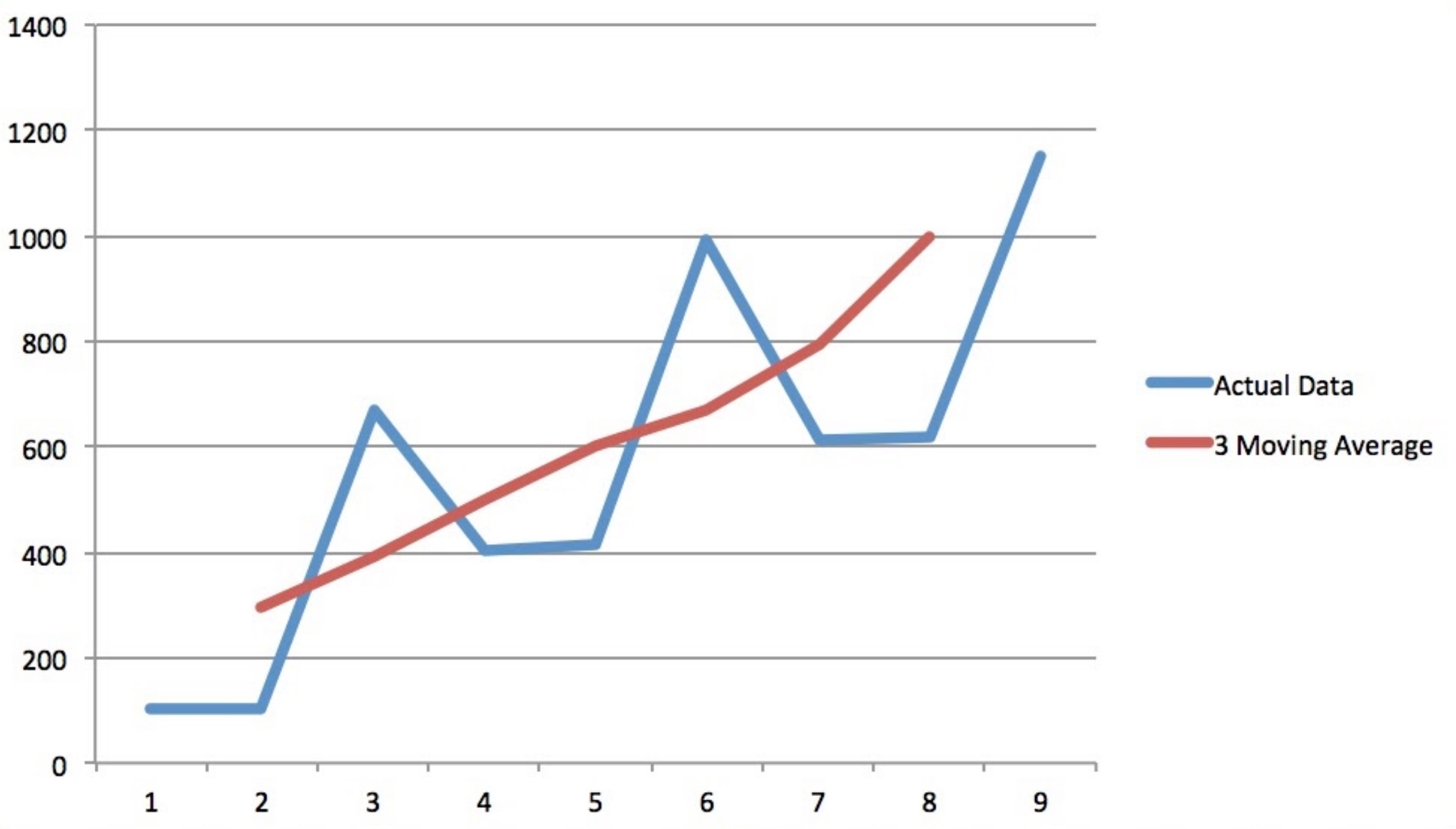
Now, let’s consider a data set which has seasonal as well as trend component below.
| Index | Actual Data | 3 Moving Average |
| 1 | 103 | |
| 2 | 105 | 293.33 |
| 3 | 672 | 393.67 |
| 4 | 404 | 497 |
| 5 | 415 | 603 |
| 6 | 991 | 672 |
| 7 | 610 | 793 |
| 8 | 617 | 995 |
| 9 | 1148 |
The next figure shows how the seasonality is removed by the moving average technique, however the trend information remains in the transformed data.
Disadvantage of this approach is that sample size gets reduced. However with a large data set that is not the problem.
2. Differencing
Differencing is a method used to remove the trend information from the time series. Once removed, data becomes stationary (i.e data fluctuates around a constant mean, independent of time, and the variance of the fluctuation remains essentially constant over time). For example, let’s consider the data below.
| Index | Actual Data | Data After Differencing |
| 1 | 2 | |
| 2 | 4 | 2 |
| 3 | 6 | 2 |
| 4 | 8 | 2 |
| 5 | 10 | 2 |
| 6 | 12 | 2 |
| 7 | 14 | 2 |
| 8 | 16 | 2 |
| 9 | 18 | 2 |
Here, the 1st element in the “Data after Differencing” column is computed by subtracting 1st element of the actual element column (with value 2) from the second element of the actual element column (with value 4) and so on. As evident from the figure below, the resulting series does not have the trend information any more. But in reality, the transformed data will consists of the error/randomness around the mean.

